声明:本文来自于微信公众号 新智元,作者:新智元,授权站长之家转载发布。
【新智元导读】长视频理解迎来新纪元!智源联手国内多所顶尖高校,推出了超长视频理解大模型Video-XL。仅用一张80G显卡处理小时级视频,未来AI看懂电影再也不是难事。
长视频理解是多模态大模型的核心能力之一,也是迈向通用人工智能(AGI)的关键一步。然而,现有的多模态大模型在处理10分钟以上的超长视频时,仍然面临性能差和效率低的双重挑战。
对此,智源研究院联合上海交通大学、中国人民大学、北京大学和北京邮电大学等多所高校,推出了小时级的超长视频理解大模型Video-XL。
Video-XL借助语言模型(LLM)的原生能力对长视觉序列进行压缩,不仅保留了短视频理解的能力,而且在长视频理解上展现了出色的泛化能力。
Video-XL相较于同等参数规模的模型,在多个主流长视频理解基准评测的多项任务中排名第一。
此外,Video-XL在效率与性能之间实现了良好的平衡,仅需一块80G显存的显卡即可处理2048帧输入(对小时级长度视频采样),并在视频「大海捞针」任务中取得了接近95%的准确率。

仅需几秒钟,VideoXL便可以准确检索长视频中植入的广告内容(https://github.com/VectorSpaceLab/Video-XL/tree/main/examples),也可以像人类一样准确理解电影中发生的主要事件(本视频仅用于学术研究,如有问题,请随时联系)
未来,Video-XL有望在电影摘要、视频异常检测、广告植入检测等应用场景中展现出广泛的应用价值,成为得力的长视频理解助手。

论文标题:Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
论文链接:https://arxiv.org/abs/2409.14485
模型链接:https://huggingface.co/sy1998/Video_XL
项目链接:https://github.com/VectorSpaceLab/Video-XL
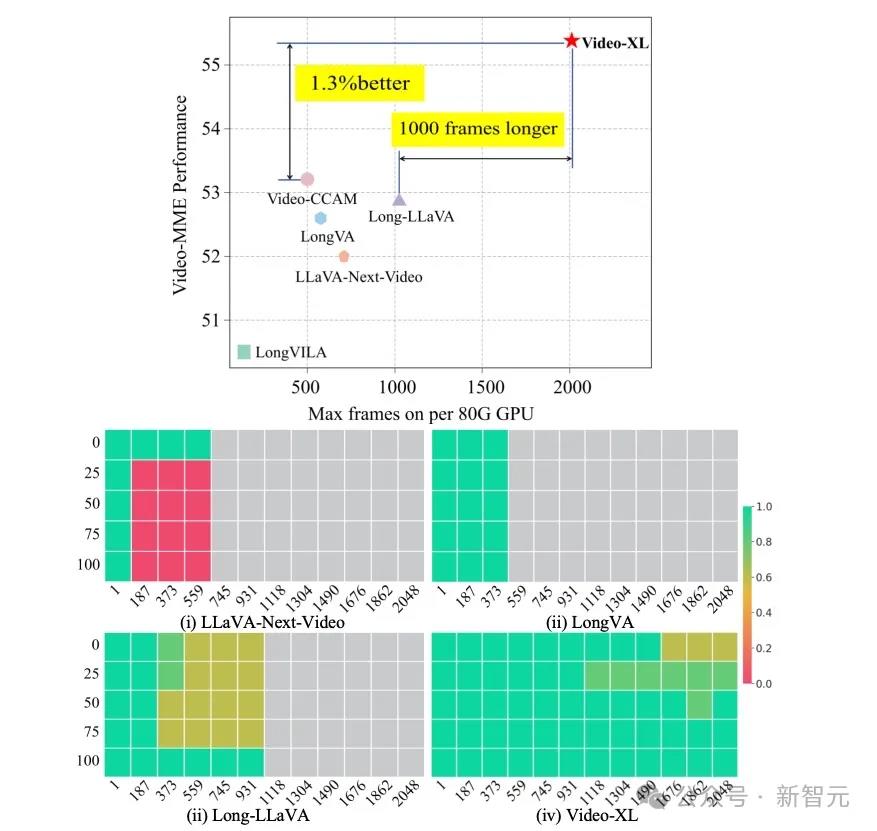
图1不同长视频模型在单块80G显卡上支持的最大帧数及在Video-MME上的表现
背景介绍
使用MLLM进行长视频理解具有极大的研究和应用前景。然而,当前的视频理解模型往往只能处理较短的视频,无法处理十分钟以上的视频。
尽管最近研究社区出现了一些长视频理解模型,但这些工作主要存在以下问题:
为了使语言模型的固定窗口长度适应长视频带来的大量视觉token,众多方法尝试设计机制对视觉token进行压缩,例如LLaMA-VID主要降低token的数量,而MovieChat,MALMM则设计memory模块对帧信息进行压缩。然而,压缩视觉信息不可避免带来信息的损失和性能降低。
相关工作LongVA尝试finetune语言模型扩大其上下文窗口,并成功将短视频理解能力泛化到了长视频上。LongVila优化了长视频训练的开销,提出了高效训练长视频训练的范式。然而,这些工作并未考虑推理时视频帧数增加带来的计算开销。
方法介绍
1.模型结构
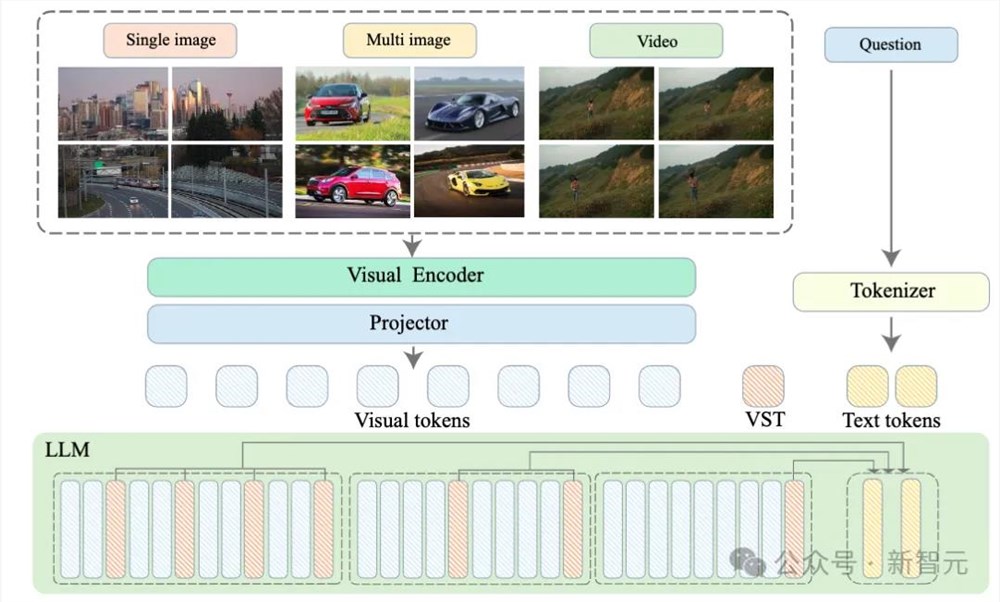
图2Video-XL模型结构图
如图2所示,Video-XL的整体模型结构和主流的MLLMs结构相似,由视觉编码器(CLIP), 视觉-语言映射器(2-layer MLP)以及语言模型(Qwen-7B)构成。
特别之处在于,为了处理各种格式的多模态数据(单图,多图和视频),Video-XL建立了一个统一的视觉编码机制。
因此,一个N帧的视频或者一个N图像块的图片都将统一标记成N×M视觉token。
2.视觉上下文隐空间压缩
相比于以往长视频模型直接对视觉token压缩,Video-XL尝试利用语言模型对上下文的建模能力对长视觉序列进行无损压缩。对于视觉语言连接器输出的视觉信号序列:
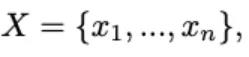
其中n为视觉token的数量。Video-XL的目标在于将X压缩成更为紧凑的视觉表示C (|C|<|X|)。在下文中将详细介绍视觉上下文隐空间压缩的原理。
受到Activation Beacon的启发,Video-XL引入了一种新的特殊标记,称为视觉摘要标记(VST),记为。基于此可以将视觉信号的隐层特征压缩到VST在LLM中的激活表示中(每层的Key和Value值)。
具体而言,首先将视觉信号序列X分成大小为w的窗口(默认每个窗口长度为1440):
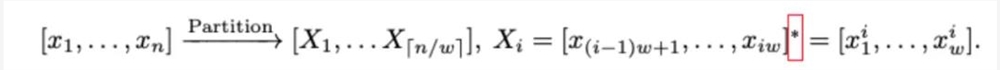
接着,对每个窗口首先确定压缩比,并插入一组VST标记,以交替的方式在视觉标记序列中插入。
在该过程中,视觉token表示的变化可以由以下公式表达:
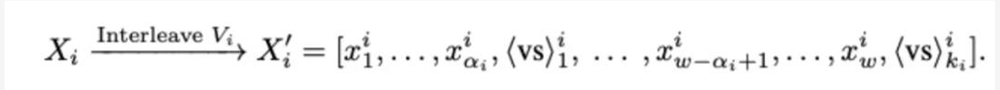
LLM将逐个处理每个窗口进行编码,并使用额外的投影矩阵在每层自注意力模块中处理VST的隐藏值。
编码完成后,普通视觉标记的激活值被丢弃,而VST的激活值被保留并累积,作为处理后续窗口时的视觉信号代理。
3.模型训练方式
Video-XL通过优化在压缩视觉信号下的生成质量来进行训练。
下一个token的预测通过以下公式进行计算:

其中Θ代表模型所有优化的参数,包含语言模型,视觉编码器、视觉语言连接器、VST的投影矩阵,以及VST的token embedding。
模型通过最小化标准的自回归损失进行训练,训练过程中不计算VST标记的损失(其标签设为-100),因为它们仅用于压缩。
同时,为了灵活支持不同的压缩粒度,训练时每个窗口的压缩比会从{2,4,8,12,16}中随机抽取。在推理时,可以根据具体的效率需求选择一个压缩比并应用于所有窗口。
4.模型训练数据
在预训练阶段,Video-XL使用Laion-2M数据集优化视觉语言连接器。
在微调阶段,Video-XL充分利用了MLLM在各种多模态数据集上的能力。
对于单图像数据,使用了Bunny695k和Sharegpt-4o的57k张图片。
对于多图像数据,使用了从MMDU提取的5k个数据。
对于视频数据,收集了不同时长的视频样本,包括来自NExT-QA的32k样本,Sharegpt-4o的2k视频样本,CinePile的10k样本以及11k个带有GPT-4V视频字幕注释的私有数据。
为了增强长视频理解能力并释放视觉压缩机制的潜力,本工作开发了一个自动化的长视频数据生产流程,并创建了一个高质量数据集——视觉线索顺序数据(VICO)。
该流程首先从CinePile数据或YouTube等视频平台获取长视频,涵盖电影、纪录片、游戏、体育等开放领域的内容。每个长视频被分割成14秒的片段。
对于每个片段,本工作使用VILA-1.540B模型生成详细描述,包括动作序列和关键事件。基于这些描述,本工作利用ChatGPT将线索按时间顺序排列。
VICO数据集通过要求模型检索关键帧并检测时间变化,提升其长视频理解能力。
实验
1.评测基准
Video-XL选用多个主流视频理解评测基准,对于长视频理解任务,评测了VNBench、LongVideoBench、MLVU和Video-MME;对于短视频理解任务,评测了MVBench和Next-QA。
2.评测结果
长视频理解:
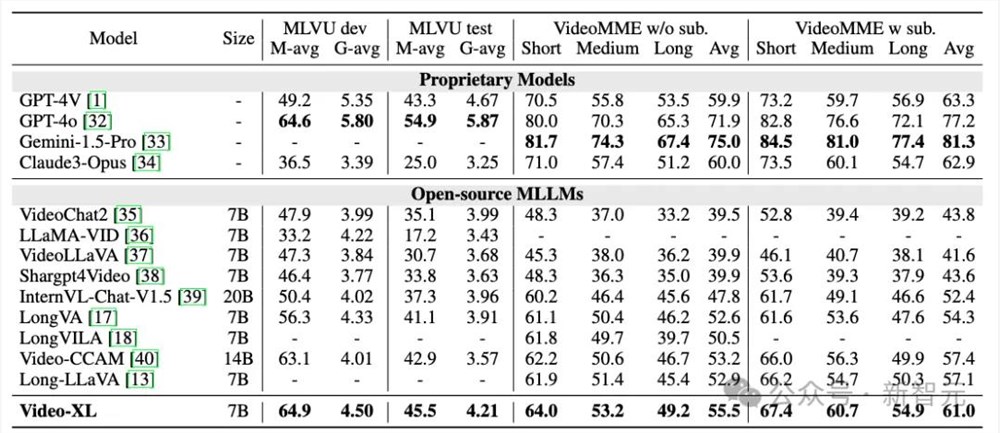
表1Video-XL在MLVU和VideoMME的性能
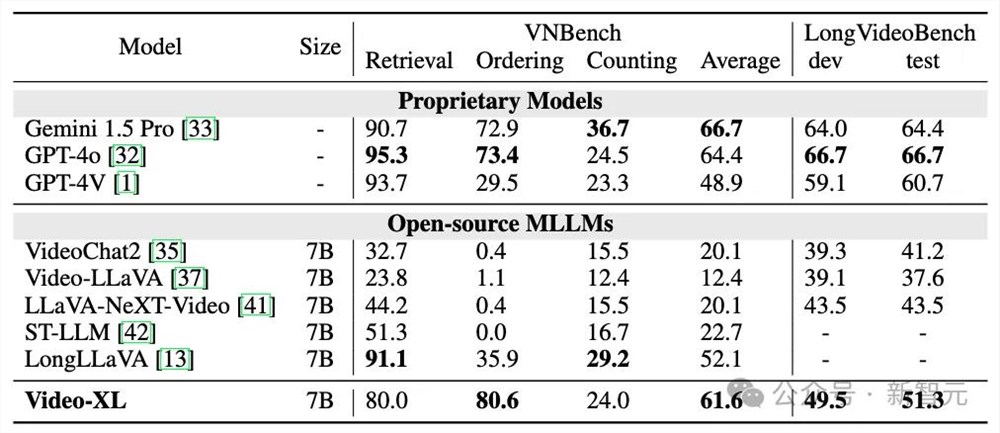
表2Video-XL在VNBench和LongVideoBench上的性能
如表1和表2所示Video-XL在多个主流的长视频评测基准上展现了卓越性能。
在VNBench上准确率超过了目前最好的长视频模型大约10%;
在MLVU的验证集上,仅仅具有7B参数的Video-XL甚至在单项选择任务上超越了GPT-4o模型;
在Video-MME和LongVideoBench等数据集上,Video-XL也在同等量级规模的长视频理解模型中排名第一。
超长视频理解:
Video-XL通过进行了视频「大海捞针」测试来评估其处理超长上下文的能力。
LLaVA-NexT-Video和LongLLaVA都采用了简单的位置信息外推算法,但在输入更多上下文时,仍然难以理解关键信息。虽然LongVA通过微调LLM来处理更长的输入,但高昂的计算成本限制了其在单块80G GPU上处理约400帧的能力。
相比之下,Video-XL在相同硬件条件下,以16倍压缩比和2048帧输入,达到了近95%的准确率。这表明,Video-XL在准确性和计算效率之间实现了最佳平衡。
短视频理解:
尽管Video-XL的设计主要面向长视频,但它保留了短视频理解的能力。在MVBench和Next-QA任务评测中,Video-XL取得了和目前SOTA模型相当的效果。
3.消融实验
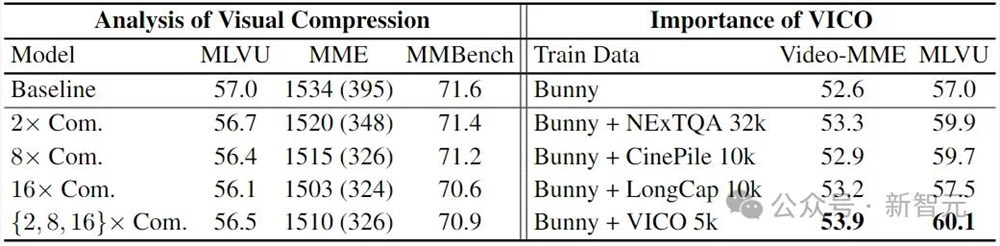
表3Video-XL的消融实验
Video-XL对所提出的视觉压缩机制和VICO数据集进行了消融实验,如表3所示。
Video-XL使用Bunny695k数据集训练了两个模型:一个不使用压缩,另一个使用随机压缩比(从{2,8,16}中选取)。
对于压缩模型,在视频基准MLVU和图像基准MME、MMBench上测试时应用了不同的压缩比。
值得注意的是,即使使用16的压缩比,压缩模型在仍表现出较好的效果,接近甚至超越了基线模型。
Video-XL使用不同数据集训练了四个模型:(a)仅使用Bunny695k;(b)Bunny695k结合NeXTQA32k;(c)Bunny695k结合CinePile10k;(d)Bunny695k结合长视频字幕5k;(e)Bunny695k结合VICO5k。
值得注意的是,即使仅使用5k的VICO数据,Video-XL也超过了使用NeXTQA32k训练的模型。
此外,主要事件/动作排序任务比字幕生成任务带来了更显著的提升,因为它促使模型从长序列中提取关键片段并进行理解。
可视化结果

图3Video-XL 在长视频理解任务上的可视化结果
如图3所示,Video-XL在电影摘要、视频异常检测、广告植入检测等长视频任务上展现了良好的性能。
总结
该工作提出了Video-XL模型,利用语言模型的压缩能力,仅需一块80G显卡即可理解小时级别的视频;除此之外,Video-XL在多个主流长视频理解基准评测上表现优异。
Video-XL有望在多个长视频理解的应用场景中展现出广泛的应用价值,成为得力的长视频理解助手。
目前,Video-XL的模型代码均已开源,以促进全球多模态视频理解研究社区的合作和技术共享。
参考资料:
https://arxiv.org/abs/2409.14485
()
(来源:站长之家)
免责声明:本站文章部分内容为本站原创,另有部分容来源于第三方或整理自互联网,其中转载部分仅供展示,不拥有所有权,不代表本站观点立场,也不构成任何其他建议,对其内容、文字的真实性、完整性、及时性不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容,不承担相关法律责任。如发现本站文章、图片等内容有涉及版权/违法违规或其他不适合的内容, 请及时联系我们进行处理。
 宣传片
宣传片
 QQ:
QQ: 微信:
微信:



 公安网备案:苏ICP备2022030477号-15苏州钰尚网络文化传媒有限公司
公安网备案:苏ICP备2022030477号-15苏州钰尚网络文化传媒有限公司