声明:本文来自于微信公众号 量子位 (ID:QbitAI),作者:鱼羊 栗子 ,授权站长之家转载发布。
一个体量仅为2B的大模型,能有什么用?
答案可能超出你的想象。
因为若是用四个字来概括,那就是“多、快、好、省”:
多:它是业界第一个在端侧部署多模态的大模型。
快:一张1080Ti可高效微调、一台机器可以持续训练。
好:性能跟体量极具反差感,在多项成绩中超越了一众主流“大体量”大模型。
省:1元=1700000tokens,成本为Mistral-Medium百分之一
那么,这个能够“以小博大”,颇有四两拨千斤意味的大模型,到底什么来头?
不卖关子,它正是由清华系初创公司面壁智能最新发布的旗舰终端大模型——MiniCPM。

并且团队还给它起了个别具一格的昵称——小钢炮。
而在众多亮点之间,最令人意外的还是小钢炮用2B的“姿势”所表现出来的性能。
例如与同样是采用“以小博大”路数的大模型标杆之作Mistral-7B做比较,小钢炮多项标准测试成绩均胜出:
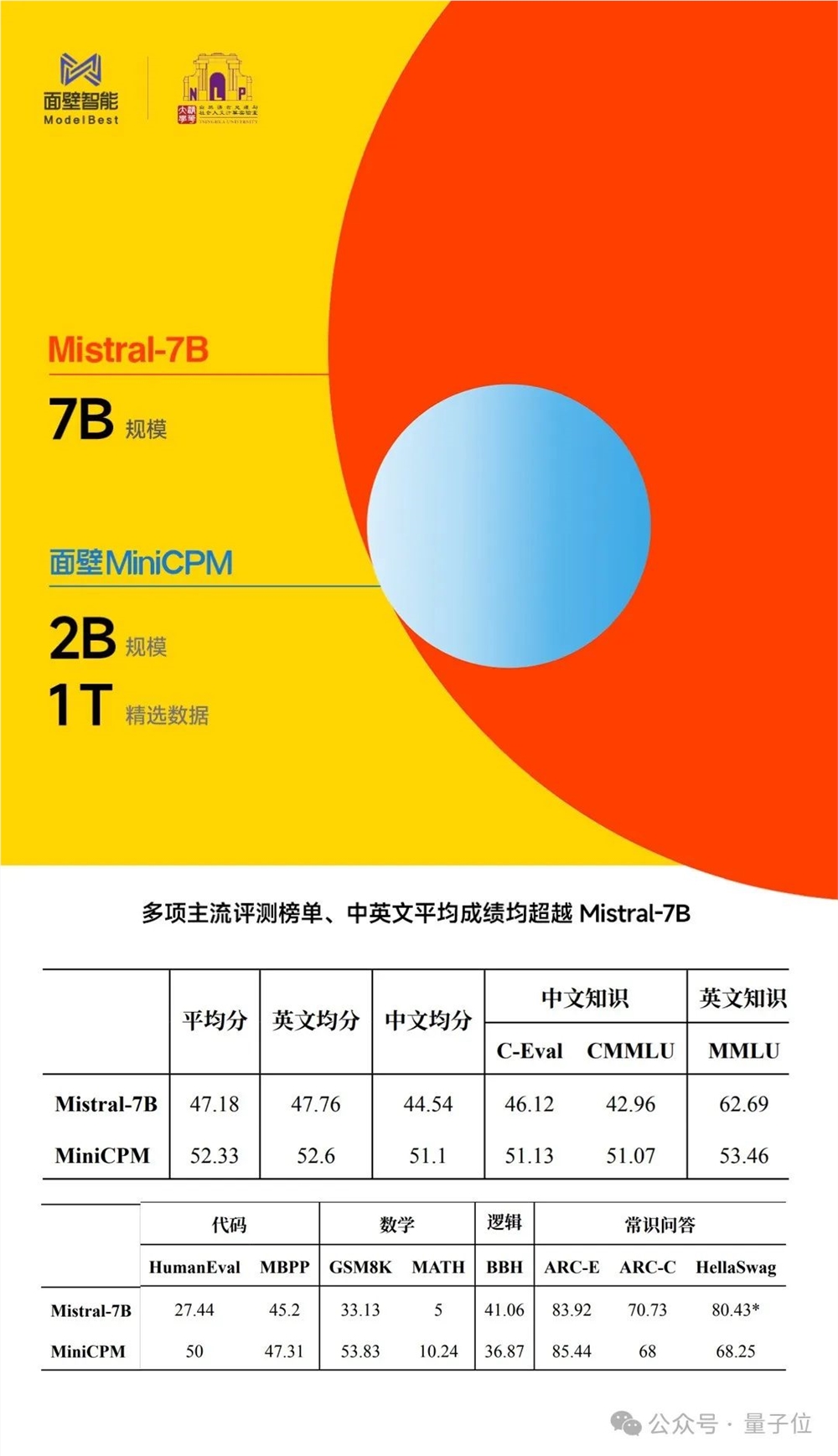
再把与小钢炮同“体量”的选手拉出来,大部分能力依旧是处于领先,并且英文能力还是较为出众的那种:
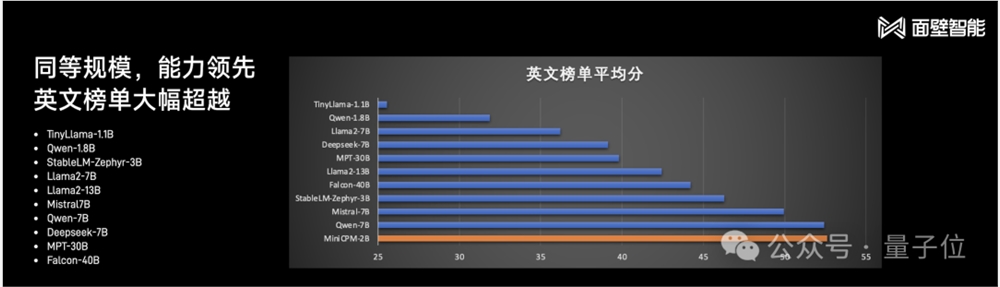
即使把Mistral-7B更大的模型拉进来同台比擂,例如Llama2-13B、MPT-13B、Falcon40B,多项成绩较为出众的仍是小钢炮:
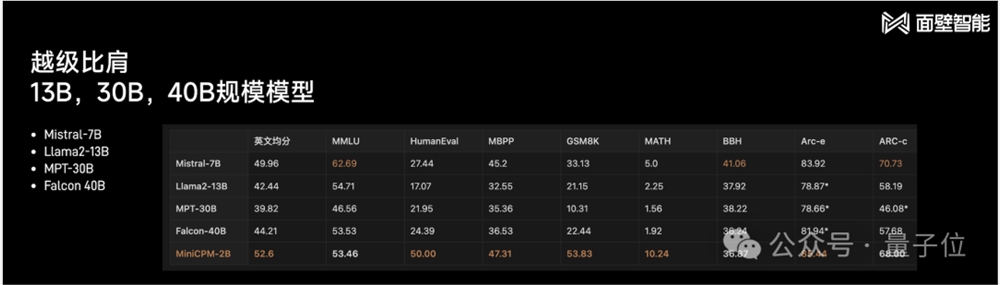
若不论大模型的尺寸,把主流的全部囊括进来,在最接近人评的测试集MT-Bench中比较,小钢炮也取得了较为不错的成绩:
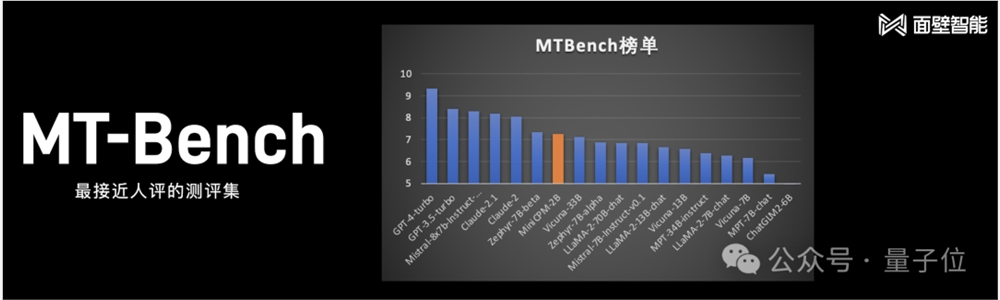
不仅如此,根据面壁智能CEO李大海的介绍:
int4量化版小钢炮,可以在闪存应用压缩75%的情况下,性能可以做到基本无损耗。
有一说一,成绩和榜单是大模型能力的一方面,但更重要的还是要看大模型在实际应用中的效果。
2B“小钢炮”效果一览
老规矩,我们还是从不同维度来看下小钢炮的实际应用效果。
中英夹杂提问,精准翻译成法语
让大模型在两种语言之间做翻译已然是件常见的事情。
团队在现场给小钢炮的翻译任务加了一把难度,中英混合提问,并要求把整句翻译成法语:
Translate this sentence into French: “I am a fresh man on Chinese, do you know how this sentence is translated: 如何用Python创建一个简单的网页爬虫?”
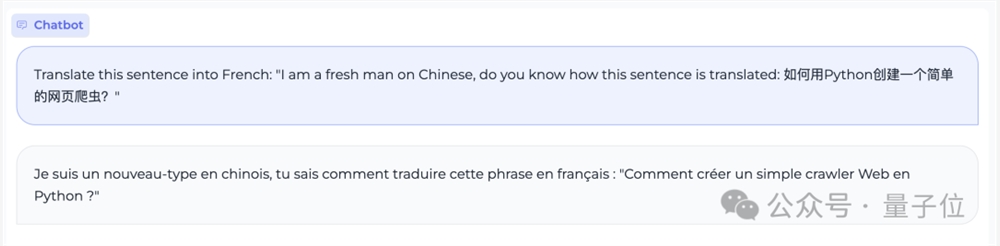
从翻译结果来看,小钢炮准确地理解了中英混合的表述,并按照要求给出了精准的法语翻译。
如果让人类给一句话添加emoji,那么过程大致是要先理解这句话,然后再在恰当的位置塞进emoji表情。
那么这个任务小钢炮是否能hold住呢?
请看结果:
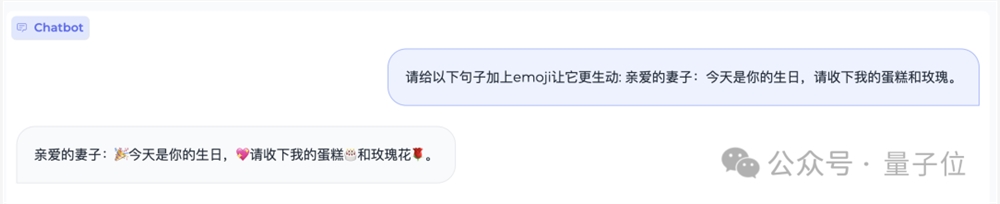
生日是要的,和也精准塞进了恰当位置,最重要是小钢炮理解到了这句话是表达爱意。
再如“山东省最高的山是那座山,它比黄山高还是矮?差距多少?”这样的问题,小钢炮也是轻松应对:

小钢炮给自己写代码
大模型对给定的任务写代码现在也是司空见惯了。
如果让大模型给自己写段代码呢?请听题:
编写一个Python程序来实现一个MiniCPM模型(Transformer结构,40层,每层维度为2304,词表大小为122753)。

小钢炮在接收到任务之后,随即开始“自己给自己写代码”,并且每一步的步骤内容也是非常清晰:导入所需库→定义模型结构→定义训练和评估函数→训练模型→评估模型性能。
多模态首次上手机
正如我们刚才提到的,小钢炮的亮点之一就是它是业界第一个在端侧部署多模态的大模型。
在现场,李大海也对此做了相应的展示。
例如先“喂”给手机里的小钢炮一张图,并提问“这个蘑菇的名字是什么?有毒么”,小钢炮就会先看图再作答:
这根蘑菇的名称是“蝇鹅膏”。它有毒,可以引起恶心、呕吐和腹泻等症状。
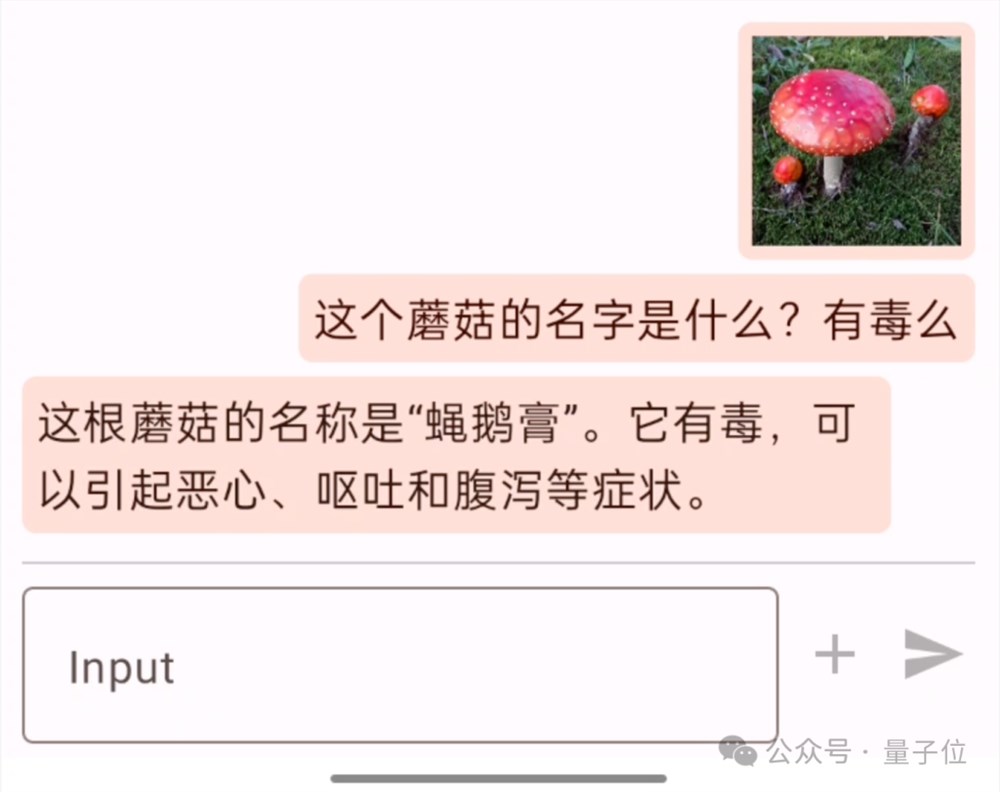
当然,连续追问、上下文对话也是不在话下:

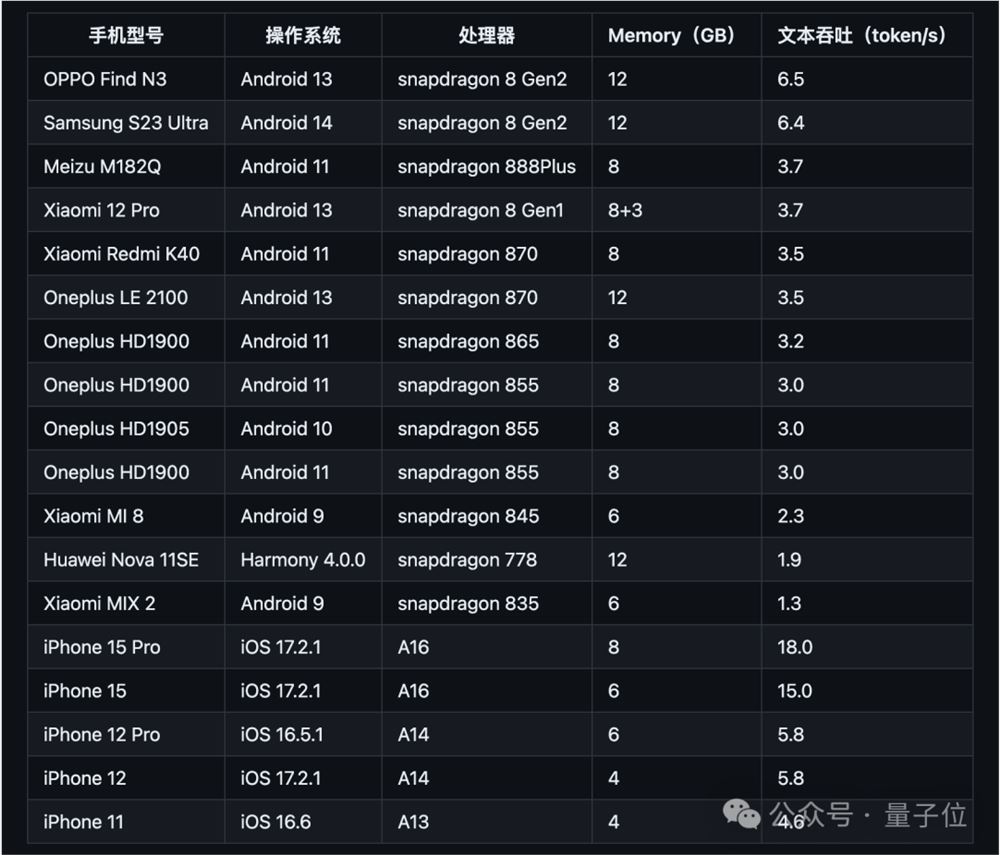
据了解,上面展示的这些能力都是在量化版小钢炮+OPPO手机+骁龙855芯片这个配置之下完成的。
之所以如此,是因为团队想要展示小钢炮是一个“省钱的大模型”。
怎么理解?
刚才手机里GPU的成本大约600元,每秒7.5tokens,假设运行5年报废,共计170万tokens,则其推理成本仅为1元。
如此,便可以得到一个成本公式:
1元=1700000tokens。
相比GPT-4的推理成本,1元=4700tokens,可以说是指数级的把价格打下去。
即便是与Mistral-medium相比,成本也是其1/100。

这次也同步开源了一个更大也更好展示多模态能力的OmniLMM-12B,玩法就变得更多了。
例如举着手机,在摄像头下方比划石头、剪刀、布,并向小钢炮提问:
我现在玩的可能是什么游戏?

小钢炮看完之后,在理解基础上便会开始作答:
你可能在玩的游戏是石头剪刀布。
然后继续给小钢炮看一眼“拳头”,并发问:
手势在游戏中是什么意思?

继续给小钢炮看一眼“拳头”,并发问:
如何在游戏中赢我?

小钢炮思考片刻后,给出了正确答案:
要在游戏中获胜,另一玩家需要出布。
值得一提的是,从上面的演示中,我们可以看到小钢炮在处理过程中是有一段时间的延迟。
现场也有人调侃说“我看这个视频演示没有加美颜”(指加速处理)。
对此,面壁智能联合创始人、清华大学副教授刘知远回答说:
没错,我们不加“美颜”,比较朴实。
而且小钢炮在多模态这块还是提高的空间的。
怎么做到的?
整体来看,面壁智能在技术路线上一直高举“高效”大旗,主要是从AI的三大要素作为突破口,即算力、算法和数据。
在算力层面上,面壁智能认为“Infra是大模型创业护城河”,Infra可以决定一家创业公司的技术上限。
若是没有一个足够“能打”的Infra,即使短期内能够打造较好的模型,但越往后、越深入时会发现很快就会遇到技术瓶颈。
因此,在早年前,团队便在业内较早地提出了BMTrain,一个分布式的高效训练框架。
有了它,很深入地优化工作就可以快速地结合Infra落地实现。
除此之外,团队陆续还推出了高效推理框架BMInf、高效压缩框架BMCook,以及高效微调框架BMTune等等。
有这些具体的工具,便形成了面壁智能在算力层面的杀手锏——面壁ModelForce,全流程优化加速套件平台。

在算法层面上,面壁智能在技术发展过程中所积累出来的利器则是面壁模型沙盒(Model Sandbox)。
这实则也是一种方法论,可以将大模型从过去的炼丹形式变成了一种实验科学。
而在历经上千次的模型沙盒实验之后,团队在算法中的各种细节上也得到了一系列业界最优配置。
例如最优批次大小(batch size),可以大幅节省大模型训练时的token量;再如所有尺寸的模型可以通过最优的超参数的配制,保证训练任意大小的模型取得最好的效果等等。
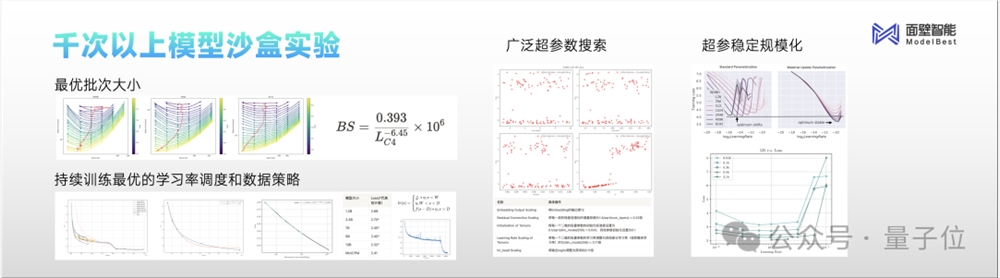
最后在数据层面上,优秀的数据也决定了大模型最后性能的成败。
而这次小钢炮的诞生,面壁智能仅仅是用了所积累的优质数据中,通过方法论所精选出来的1T。
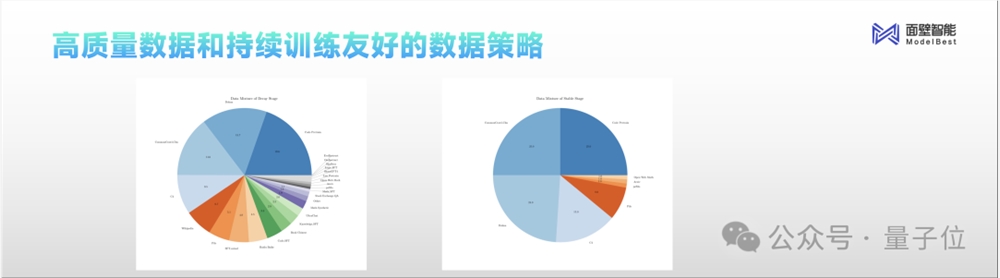
值得一提的是,为了行业更好的交流和发展,面壁智能开源了训练、退火两个阶段来的数据配方来供参考。
除此之外,与小钢炮相关的更多技术细节以及如何在手机上部署的教程等,均已经在GitHub中开源。

感兴趣的小伙伴,可以在文末链接处了解更多详情~
不过最后,还有一个问题值得讨论来一波:
大模型,为什么往“小”了搞?
其实在2023年,在大模型以小博大方面,便已经开始有了苗头。
最为典型的,就是小钢炮此次对标的Mistral-7B。
在它刚刚出道之际,便以更小的“姿势”击败了更大体量的Llama2-13B、Llama1(34B)等一众大模型。
这就为“比大更大”内卷下的模型圈带来了一定启发。

不过在此背后,大模型往“小”了做,所体现的是一种更大的趋势。
一方面,从大模型从2022年底爆火至今,一个非常明显的变化就是从专注训练,逐渐转向推理。
这是一个技术发展必然的结果,要从比性能和结果,到比谁的大模型更好用;而这个“用”,最好、最直接的体现就应当是在端侧谁可以更“多快好省”地运行。
对此,李大海表示:
站在大模型时代之下,我们都在提的一个概念便是“AI原生应用”;这个时代需要的全新操作系统,就是AI原生应用+AI原生硬件。
而其中的AI原生硬件,其实很简单,就是只要能在端侧运行大模型的硬件就是原生硬件。
因此,端侧的大模型就显得格外重要。
另一方面,市场的表现也是印证大模型往“小”发展的一点。
自从去年7月开始,非常明显的一点是,众多主流手机厂商、PC、汽车品牌,陆续在宣布接入大模型。
手机厂商例如华为、小米、荣耀、OPPO、Vivo、三星等;车企包括小鹏、蔚来、理想、吉利等等。
需求之大,可见一斑。
值得一提的是,从小钢炮在GitHub开源的内容来看,目前它已经在众多品牌的老机型上做了部署实验。
因此,老手机上跑大模型也成为了一种可能。
不过细心的朋友也注意到了,面壁智能其实从成立至今,也仅有短短一年的时间。
这就不禁让人发问:一年时间是如何在技术上做到的这般突破?
其实在此背后,更多的是清华系成员们在公司成立之前,长久以来在技术上的积累与跟进。
早在2018年,面壁智能的核心技术团队在BERT发布之后,便聚焦在清华NLP实验的相关工作,发布过全球首个知识指导的预训练模型ERNIE。
随后在2020年,他们也作为“悟道”大模型首发主力阵容发布了全球第一个20亿级中文开源大模型CPM1,也持续参与了之后的CPM2和CPM3。
除此之外,在2022年,在开源相关工作中,面壁智能核心成员也参与到了OpenBMB开源社区的成立与运作。
由此可见,面壁智能的核心技术成员是属于中国最早进行大模型研究的那一批。

正是基于这样的技术积累,也就不难理解面壁智能为何能够在短短一年时间内交出如此之多的“作业”了:

据了解,截至目前,面壁智能拥有100多人的科研团队。
虽然平均年龄仅为28岁,但清北含量高达80%,也有来自阿里、字节、百度等国内外知名大厂的工程团队。
加上团队还主打一个“双CP”组合,即大将里的“小哥哥”+“小鲜肉”里的大将,这种经验与创新的碰撞,或许也是推动发展进程的原动力之一。
诚然,开年小钢炮的发布给大模型带来了不少惊艳,但也正如团队所说,相关工作还有许多需要改进之处。
因此面壁智能在接下来的新进展,是值得关注的。
One More Thing
在小钢炮发布现场,一张五道口大模型Valley图格外吸睛。
用李大海的话来说:
这是全中国大模型最密集的地区。
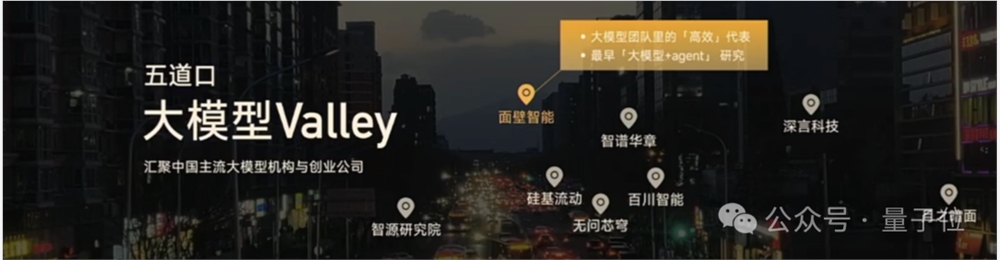
嗯,五道口,不愧是“宇宙中心”。
开源地址(内含技术报告):
MiniCPM GitHub:
https://github.com/OpenBMB/MiniCPM
OmniLMM GitHub:
https://github.com/OpenBMB/OmniLMM
—完—
()
(来源:站长之家)
免责声明:本站文章部分内容为本站原创,另有部分容来源于第三方或整理自互联网,其中转载部分仅供展示,不拥有所有权,不代表本站观点立场,也不构成任何其他建议,对其内容、文字的真实性、完整性、及时性不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容,不承担相关法律责任。如发现本站文章、图片等内容有涉及版权/违法违规或其他不适合的内容, 请及时联系我们进行处理。
 宣传片
宣传片
 QQ:
QQ: 微信:
微信:



 公安网备案:苏ICP备2022030477号-15苏州钰尚网络文化传媒有限公司
公安网备案:苏ICP备2022030477号-15苏州钰尚网络文化传媒有限公司